Connect with Us!
All Quiet on the Cloud Farms

If feels like we’ve been through the wars, through the grinder, been churned up, chewed up and mashed up. It’s amazing what changing the entire application technology stack can do for you. It’s also amazing what it can do to you.
As you can see from the chart above, our days have been somewhat turbulent recently, fortunately that’s all changed in the past 48 hours.
Ever since we decided to move Affino to an auto-scaling platform we knew there would come a period of bedding in. Typically when we embrace a new technology, we isolate it during its introduction so that we can see exactly how it impacts on the overall setup. It was clear that with the move to auto-scaling we could not do that. So instead we went all in.
All Change
In practice we’ve introduced: Ubuntu, Apache, Tomcat, ColdFusion 10, Scalr, Solr, Nginx, AWS monitoring, and a number of in-house developed solutions all in one go. We’ve also completely changed how we architect our cloud setup with separate application, search and file repository nodes. Just to make things more interesting we’ve also launched two major Affino releases, and all the key social platforms have completely overhauled their APIs during the period we’ve been transitioning to the new cloud setup. Oh yes, we’ve also had to re-architect our on-site and off-site backup setups.
It’s little wonder then that we’ve had some turbulence since the launch of Affino 7.1, and moving all the Affino SaaS instances to the new cloud.
Farming in the Cloud
The move to Scaling Farms has been one where 20 years of experience in managing and running systems and networks is as much a handicap as it is a benefit. There’s a great deal that needs to be un-learned, and it’s been essential to throw out all our assumptions.
Much of what is great for keeping servers up when they’re under pressure, is the opposite of what needs doing when you’re running cloud farms with disposable nodes. It’s often much better to have a fast-failover and fast-scale than have a server pushed to the limits with reduced response times.
The past two months have been an exercise in pushing limits and failing fast in every way possible most days, nights and weekends. The Affino 7.2 release resolved hundreds of issues with the core Affino platform, and we have spent hundreds of man-hours re-architecting the infrastructure, optimising hardware, tuning the monitoring, developing our own monitoring solutions, read thousands of forum posts and articles, and written a fair few of our own.
And finally we have the result we were aiming for.
When Flatlining is a Good Thing
There’s few things better than seeing a steady state on a server farm, the only thing better is being able to reduce the number of nodes to a minimum and seeing that flatline as well.
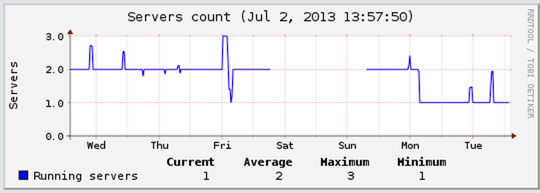
The above chart shows one farm which was previously bouncing between two and three nodes, and is now down to one node with the occasional up-scaling to handle additional load when required.
What’s not apparent from the charts is that previously we were having site downtime periods where it was taking between one and two minutes for the up-scaling to occur. Technically there was no downtime, but the sites were not responding fast enough.
We also occasionally suffered from Zombie nodes, servers which although on the surface were running entirely normally in practice they were no longer serving pages. This meant that we were scaling up to server the same level of traffic.
Bringing together the application servers, monitoring solutions, auto-scaling platform and load-balancers in one seamless responsive setup has been a major tuning exercise. In fact it’s amazing how important getting everything synchronised right down to the second has been. The slightest tweak on any one of the systems has meant a complete review of it’s impact on all the other systems.
When it’s working right though you get this:
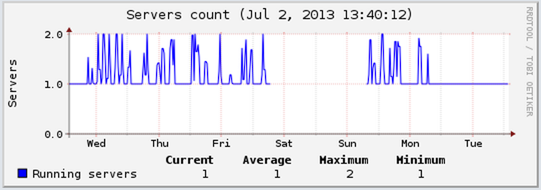
Affino - Optimised
The intensity of the optimisation effort, and our drive to resolve all the uptime issues we were facing has had one quite very satisfying outcome. Affino has never been more optimised to scale. Farms which previously were running at high CPU loads are now at a fraction of the level.
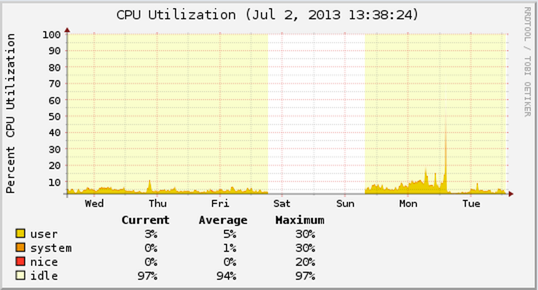
We’re not taking anything for granted yet, and we fully expect more system shocks in the future, but it definitely feels like the end of the beginning. Although we’ve been left a bit frazzled by the whole experience, the wealth of knowledge and our ability to tackle shocks has improved exponentially from where it was before.
The best outcome of the whole exercise has been that although we still have multiple team members on watch around the clock, virtually all system issues are now automatically resolved with no human intervention. This means greatly improved up-times and response times all round.
From Backend to Frontend
We’re now about to embark on a new exercise of the same scale on the Affino Frontend with the move from fixed Skins to fully Responsive page designs.
It means ripping up all the page design, page generation, coding practices, page serving, styles and forms, templates, Design Elements, media interfaces, CSS and JavaScript generation. And on top of that we’re moving to JQuery 2 and TinyMCE 4.
We fully expect the outcomes to be just as good and a great deal less turbulent.
Related
How does auto-scaling improve server response times?What benefits arise from using a cloud-based architecture?How can fast-failover enhance system reliability in cloud farms?What optimizations were implemented to reduce CPU loads?How will responsive design impact Affino's frontend performance?
Did you find this content useful?
Thank you for your input
Thank you for your feedback




Upcoming and Former Events

Webinar - Introducing Affino's Fourth Generation AI Services

Webinar - Enhanced Affino Commerce & Subscription Capabilities

Webinar - All About the New Affino Control Centre

Affino Innovation Briefing 2024
Driving business at some of the world's most forward thinking companies







Our Chosen Charity
![]()
Meetings:
Google Meet and Zoom
Venue:
Soho House, Soho Works +
Registered Office:
55 Bathurst Mews
London, UK
W2 2SB
© Affino 2025